Nhắc lại, xác suất là thước đo độ không chắc chắn của các hiện tượng khác nhau . Giống như, nếu bạn ném một con xúc xắc, kết quả có thể xảy ra của nó, được xác định bởi xác suất. Phân phối này có thể được xác định với bất kỳ thử nghiệm ngẫu nhiên nào mà kết quả của nó không chắc chắn hoặc không thể dự đoán được. Bây giờ chúng ta hãy thảo luận về định nghĩa, chức năng, công thức và các loại của nó ở đây, cùng với cách tạo một bảng xác suất dựa trên các biến ngẫu nhiên.
Contents
Định nghĩa phân phối xác suất
Phân phối xác suất mang lại các kết quả có thể xảy ra cho bất kỳ sự kiện ngẫu nhiên nào. Nó cũng được xác định dựa trên không gian mẫu cơ bản như một tập hợp các kết quả có thể có của bất kỳ thử nghiệm ngẫu nhiên nào. Các cài đặt này có thể là một tập hợp các số thực hoặc một tập các vectơ hoặc tập hợp bất kỳ thực thể nào. Nó là một phần của xác suất và thống kê.
Thí nghiệm ngẫu nhiên được định nghĩa là kết quả của một thí nghiệm mà kết quả của nó không thể dự đoán được. Giả sử, nếu chúng ta tung một đồng xu, chúng ta không thể dự đoán được kết quả của nó, nó sẽ xuất hiện như thế nào hoặc nó sẽ đến như Đầu hoặc Đuôi. Kết quả có thể có của một thí nghiệm ngẫu nhiên được gọi là kết quả. Và tập hợp các kết quả được gọi là điểm mẫu. Với sự trợ giúp của các thí nghiệm hoặc sự kiện này, chúng ta luôn có thể tạo bảng mẫu xác suất về biến và xác suất.
Phân phối xác suất của các biến ngẫu nhiên
Một biến ngẫu nhiên có phân phối xác suất, xác định xác suất của các giá trị chưa biết của nó. Các biến ngẫu nhiên có thể rời rạc (không phải hằng số) hoặc liên tục hoặc cả hai. Điều đó có nghĩa là nó lấy bất kỳ danh sách giá trị hữu hạn hoặc đếm được đã chỉ định nào, được cung cấp với tính năng hàm khối lượng xác suất của phân phối xác suất của biến ngẫu nhiên hoặc có thể lấy bất kỳ giá trị số nào trong một khoảng hoặc tập hợp các khoảng. Thông qua một hàm mật độ xác suất đại diện cho phân phối xác suất của biến ngẫu nhiên hoặc nó có thể là sự kết hợp của cả rời rạc và liên tục.
Hai biến ngẫu nhiên có phân phối xác suất bằng nhau có thể khác nhau về mối quan hệ của chúng với các biến ngẫu nhiên khác hoặc liệu chúng có độc lập với các biến này hay không. Việc thừa nhận một biến ngẫu nhiên, có nghĩa là, kết quả của việc chọn ngẫu nhiên các giá trị theo hàm phân phối xác suất của biến, được gọi là các biến ngẫu nhiên.
Các loại phân phối xác suất
Có hai loại phân phối xác suất được sử dụng cho các mục đích khác nhau và các loại khác nhau của quá trình tạo dữ liệu.
-
-
- Phân phối xác suất bình thường hoặc tích lũy
- Phân phối xác suất nhị thức hoặc rời rạc
-
Bây giờ chúng ta hãy thảo luận về cả hai loại cùng với định nghĩa, công thức và ví dụ của nó.
Phân phối xác suất tích lũy
Phân phối xác suất tích lũy còn được gọi là phân phối xác suất liên tục. Trong phân phối này, tập hợp các kết quả có thể có có thể nhận các giá trị trên một phạm vi liên tục.
Ví dụ, một tập hợp các số thực, là một phân phối liên tục hoặc chuẩn, vì nó cho tất cả các kết quả có thể có của các số thực. Tương tự, tập hợp số phức, tập hợp số nguyên tố, tập hợp các số nguyên, v.v. là những ví dụ của phân phối Xác suất Chuẩn. Ngoài ra, trong các tình huống thực tế, nhiệt độ trong ngày là một ví dụ về xác suất liên tục. Dựa trên những kết quả này, chúng ta có thể tạo một bảng phân phối. Một hàm mật độ xác suất mô tả nó. Công thức cho phân phối chuẩn là;
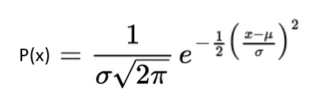
Ở đâu,
-
-
- μ = Giá trị Trung bình
- σ = Phân phối chuẩn của xác suất.
- Nếu trung bình (μ) = 0 và độ lệch chuẩn (σ) = 1, thì phân phối này được gọi là phân phối chuẩn.
- x = Biến ngẫu nhiên bình thường
-
Ví dụ về phân phối bình thường
Vì thống kê phân phối chuẩn ước tính rất tốt nhiều sự kiện tự nhiên, nên nó đã phát triển thành một tiêu chuẩn đề xuất cho nhiều truy vấn xác suất. Một số ví dụ là:
-
-
- Chiều cao của dân số thế giới
- Lăn xúc xắc (một lần hoặc nhiều lần)
- Để đánh giá mức độ thông minh của trẻ em trong thế giới cạnh tranh này
- Tung đồng xu
- Phân phối thu nhập trong nền kinh tế các nước giữa người nghèo và người giàu
- Kích thước của giày nữ
- Cân nặng của trẻ mới sinh trong khoảng
- Báo cáo trung bình của Học sinh dựa trên thành tích của họ
-
Phân phối xác suất rời rạc
Một phân phối được gọi là phân phối xác suất rời rạc, trong đó tập hợp các kết quả có bản chất là rời rạc.
Ví dụ, nếu một con xúc xắc được tung lên, thì tất cả các kết quả có thể xảy ra là rời rạc và đưa ra rất nhiều kết quả. Đây còn được gọi là các hàm khối lượng xác suất.
Vì vậy, các kết quả của phân phối nhị thức bao gồm n phép thử lặp lại và kết quả có thể xảy ra hoặc không. Công thức phân phối nhị thức là;
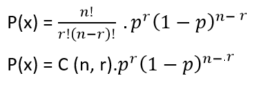
Ở đâu,
-
-
- n = Tổng số sự kiện
- r = Tổng số sự kiện thành công.
- p = Thành công trên một xác suất thử nghiệm duy nhất.
- n C r = [n! / r! (n − r)]!
- 1 – p = Xác suất Thất bại
-
Ví dụ về phân phối nhị thức
Như chúng ta đã biết, phân phối nhị thức cung cấp khả năng có một tập hợp các kết quả khác nhau. Trong thực tế, khái niệm này được sử dụng cho:
-
-
- Để tìm số lượng nguyên vật liệu đã sử dụng và chưa sử dụng trong khi sản xuất một sản phẩm.
- Để thực hiện một cuộc khảo sát về phản hồi tích cực và tiêu cực từ mọi người về bất cứ điều gì.
- Để kiểm tra xem một kênh cụ thể được bao nhiêu người xem bằng cách tính toán khảo sát CÓ / KHÔNG.
- Số lượng nam và nữ làm việc trong một công ty.
- Để đếm số phiếu bầu cho một ứng cử viên trong một cuộc bầu cử và nhiều cuộc bầu cử khác.
-
Phân phối nhị thức phủ định là gì?
Trong lý thuyết xác suất và thống kê, nếu trong một phân phối xác suất rời rạc, số lần thành công trong một loạt các thử nghiệm Bernoulli độc lập và phổ biến giống nhau trước khi một số lần thất bại cụ thể xảy ra, thì nó được gọi là phân phối nhị thức âm. Ở đây số lần thất bại được ký hiệu là ‘r’. Ví dụ, nếu chúng ta ném một con xúc xắc và xác định sự xuất hiện của 1 là thất bại và tất cả các không phải 1 là thành công. Bây giờ, nếu chúng ta ném một con xúc xắc thường xuyên cho đến khi số 1 xuất hiện lần thứ ba, tức là = ba lần thất bại, thì phân phối xác suất của số lượng không phải 1 xuất hiện sẽ là phân phối nhị thức âm.
Phân phối xác suất Poisson là gì?
Phân phối xác suất Poisson là một phân phối xác suất rời rạc biểu thị xác suất của một số sự kiện nhất định xảy ra trong một thời gian hoặc không gian cố định nếu những trường hợp này xảy ra với một tốc độ ổn định đã biết và riêng lẻ của thời gian kể từ sự kiện cuối cùng. Nó được đặt tên theo nhà toán học người Pháp Siméon Denis Poisson. Phân phối Poisson cũng có thể được thực hành cho số lượng sự kiện xảy ra trong các khoảng thời gian cụ thể khác như khoảng cách, diện tích hoặc thể tích. Một số ví dụ thực tế là:
-
-
- Một số bệnh nhân đến phòng khám từ 10 đến 11 giờ sáng.
- Số lượng email mà người quản lý nhận được giữa giờ hành chính.
- Số táo được một chủ cửa hàng bán ra trong khoảng thời gian từ 12 giờ đêm đến 4 giờ chiều hàng ngày.
-
Công thức
| Phân phối nhị thức | P (X) = n C x a x b n-x
Trong đó a = xác suất thành công b = xác suất thất bại n = số lần thử x = biến ngẫu nhiên biểu thị thành công |
| Chức năng phân phối tích lũy | FX( x ) =∫x– ∞fX( t ) dt |
| Phân phối xác suất rời rạc | P( x ) =n !r ! ( n – r ) !⋅pr( 1 – p)n – rP( x ) = C( n , r ) ⋅pr( 1 – p)n – r |
Hàm phân phối xác suất
Một hàm được sử dụng để xác định phân phối xác suất được gọi là hàm phân phối xác suất. Tùy thuộc vào các loại, chúng ta có thể xác định các chức năng này. Ngoài ra, các hàm này được sử dụng dưới dạng hàm mật độ xác suất cho bất kỳ biến ngẫu nhiên nào đã cho.
Trong trường hợp Phân phối chuẩn , hàm của một biến ngẫu nhiên có giá trị thực X là hàm được cho bởi;
F X (x) = P (X ≤ x)
Trong đó P thể hiện xác suất để biến ngẫu nhiên X xảy ra trên giá trị nhỏ hơn hoặc bằng giá trị của x.

Đối với một khoảng đóng, (a → b), hàm xác suất tích lũy có thể được định nghĩa là;
P (a <X ≤ b) = F X (b) – F X (a)
Nếu chúng ta biểu thị, hàm xác suất tích lũy dưới dạng tích phân của hàm mật độ xác suất f X , thì
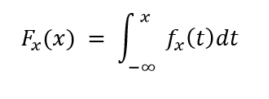
Trong trường hợp biến ngẫu nhiên X = b, chúng ta có thể xác định hàm xác suất tích lũy là;
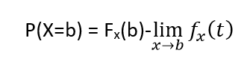
Trong trường hợp phân phối Nhị thức , như chúng ta biết, nó được định nghĩa là xác suất của khối lượng hoặc biến ngẫu nhiên rời rạc cho chính xác một giá trị nào đó. Phân phối này còn được gọi là phân phối khối lượng xác suất và hàm kết hợp với nó được gọi là hàm khối lượng xác suất.
Hàm khối lượng xác suất về cơ bản được định nghĩa cho các biến ngẫu nhiên vô hướng hoặc đa biến có miền biến thiên hoặc rời rạc. Hãy để chúng tôi thảo luận về công thức của nó:
Giả sử một biến ngẫu nhiên X và không gian mẫu S được xác định là;
X: S → A
Và A ∈ R, trong đó R là biến ngẫu nhiên rời rạc.
Khi đó, hàm khối lượng xác suất f X : A → [0,1] đối với X có thể được định nghĩa là;
f X (x) = P r (X = x) = P ({s ∈ S: X (s) = x})
Bảng phân phối xác suất
Bảng có thể được tạo dựa trên biến ngẫu nhiên và các kết quả có thể xảy ra. Giả sử, biến ngẫu nhiên X là một hàm có giá trị thực có miền là không gian mẫu của một thử nghiệm ngẫu nhiên. Phân phối xác suất P (X) của một biến ngẫu nhiên X là hệ thống các số.
| X | X 1 | X 2 | X 3 | ………… .. | X n |
| P (X) | P 1 | P 2 | P 3 | …………… | P n |
trong đó Pi> 0, i = 1 đến n và P1 + P2 + P3 + …… .. + Pn = 1
Xác suất Trước là gì?
Trong kết luận thống kê Bayes, phân phối xác suất trước, còn được gọi là trước đó, của một đại lượng không thể đoán trước là phân phối xác suất, thể hiện niềm tin của một người về đại lượng này trước khi bất kỳ bằng chứng nào được đưa vào hồ sơ. Ví dụ, phân phối xác suất trước đại diện cho tỷ lệ tương đối của những cử tri sẽ bỏ phiếu cho một chính trị gia nào đó trong cuộc bầu cử sắp tới. Đại lượng ẩn có thể là một tham số của thiết kế hoặc một biến có thể có chứ không phải là một biến có thể cảm nhận được.
Xác suất Posterior là gì?
Xác suất hậu là khả năng một sự kiện sẽ xảy ra sau khi tất cả dữ liệu hoặc thông tin cơ bản đã được tính đến. Nó gần như được liên kết với một xác suất trước, nơi một sự kiện sẽ xảy ra trước khi bạn xem xét bất kỳ dữ liệu hoặc bằng chứng mới nào. Nó là một sự điều chỉnh của xác suất trước. Chúng tôi có thể tính toán nó bằng cách sử dụng công thức dưới đây:
Xác suất sau = Xác suất trước + Bằng chứng mới
Nó thường được sử dụng trong thử nghiệm giả thuyết Bayes. Ví dụ, dữ liệu cũ đề xuất rằng khoảng 60% sinh viên bắt đầu vào đại học sẽ tốt nghiệp trong vòng 4 năm. Đây là xác suất trước. Tuy nhiên, nếu chúng tôi nghĩ rằng con số này thấp hơn nhiều, vì vậy chúng tôi bắt đầu thu thập dữ liệu mới. Dữ liệu được thu thập ngụ ý rằng con số thực gần với 50%, đó là xác suất sau.
Các ví dụ đã giải quyết
Ví dụ 1 :
Một đồng xu được tung hai lần. X là biến ngẫu nhiên của số đầu thu được. Phân phối xác suất của x là gì?
Giải pháp:
Đầu tiên hãy viết, giá trị của X = 0, 1 và 2, vì có khả năng là
Không có đầu đến
Một đầu và một đuôi đi kèm
Và đầu có cả hai đồng tiền
Bây giờ phân phối xác suất có thể được viết dưới dạng;
P (X = 0) = P (Đuôi + Đuôi) = ½ * ½ = ¼
P (X = 1) = P (Đầu + Đuôi) hoặc P (Đuôi + Đầu) = ½ * ½ + ½ * ½ = ½
P (X = 2) = P (Đầu + Đầu) = ½ * ½ = ¼
Chúng ta có thể đặt các giá trị này dưới dạng bảng;
| X | 0 | 1 | 2 |
| P (X) | 1/4 | 1/2 | 1/4 |
Ví dụ 2:
Trọng lượng của một chậu nước được chọn là một biến ngẫu nhiên liên tục. Bảng sau đây cho biết khối lượng tính bằng kg của 100 thùng chứa được máy lọc nước đổ đầy gần đây. Nó ghi lại các giá trị quan sát của biến ngẫu nhiên liên tục và các tần số tương ứng của chúng. Tìm xác suất hoặc cơ hội cho mỗi loại trọng lượng.
| Trọng lượng W | Số lượng thùng chứa |
| 0,900−0,925 | 1 |
| 0,925−0,950 | 7 |
| 0,950−0,975 | 25 |
| 0,975−1,000 | 32 |
| 1.000−1.025 | 30 |
| 1.025−1.050 | 5 |
| Toàn bộ | 100 |
Giải pháp:
Đầu tiên, chúng tôi chia số lượng thùng chứa trong mỗi loại trọng lượng cho 100 để tính xác suất.
| Trọng lượng W | Số lượng thùng chứa | Xác suất |
| 0,900−0,925 | 1 | 0,01 |
| 0,925−0,950 | 7 | 0,07 |
| 0,950−0,975 | 25 | 0,25 |
| 0,975−1,000 | 32 | 0,32 |
| 1.000−1.025 | 30 | 0,30 |
| 1.025−1.050 | 5 | 0,05 |
| Toàn bộ | 100 | 1,00 |
Tải xuống Ứng dụng học tập của BYJU’S và nhận các video liên quan và tương tác để học.
Câu hỏi thường gặp – Câu hỏi thường gặp
Phân phối xác suất là gì?
Ví dụ về phân phối xác suất là gì?
P (0) = ¼
P (1) = ½
P (2) = 1/4
P (x) = ¼ + ½ + ¼ = 1
Phân phối xác suất được sử dụng để làm gì?
Tầm quan trọng của phân phối Xác suất trong Thống kê là gì?
Các điều kiện của phân phối Xác suất là gì?
Xác suất cho các sự kiện ngẫu nhiên phải nằm trong khoảng từ 0 đến 1.
Tổng tất cả các xác suất của kết quả phải bằng 1.